Final Technical Report
Chris Hua | 2024-09-16
This post describes Tincans' research in pursuit of a real-time AI voice system, largely performed from January to April 2024. We detail four main contributions and release code for each component.
- Joint speech-language model (Gazelle)
- Real-time orchestration framework (Gondola)
- Integrated turn-taking and backchannel prediction model
- Amortized prefill
We demonstrated the first two components in April 2024, with a demo of sub-500ms AI voice chat on consumer hardware. At the time, it was the fastest public system.
Presenting: the world's fastest AI voice chat - 500ms latency, running locally, 2x faster than anyone else.
— chris (@hingeloss) April 17, 2024
How is this possible? 👇 pic.twitter.com/6J0o3am6Ab
The previously undisclosed components are parts of an overall voice chat system capable of real-time duplex chat. The components can be tuned and created cheaply, leveraging existing pretrained models. Constraints breed creativity; we hope that these techniques and code offer inspiration to others.
Looking for software engineering roles? Practice interviewing and get a better job with Parahack, the world's best AI tutor!
Gazelle
Gazelle is a joint speech-language model which accepts audio natively. We have previously documented it, see our architecture announcement and model release. We also previously opensourced checkpoints and code. Here, we offer previously undescribed training details.
Data pipeline
Training joint speech-language models (SLMs) presents unique data challenges:
- Limited suitable datasets: Most academic speech datasets focus solely on Automatic Speech Recognition (ASR).
- Performance issues: SLMs trained on these datasets often struggle with instruction following, reverting to transcription for out-of-domain tasks.
- Synthetic voice limitations: Models trained exclusively on synthetic voices perform poorly with live voices.
- Single channel data: Nearly all audio on the internet mixes speakers together, which makes makes it difficult to distinguish speaker turns.
To sum it up, you want real data, but there's just never enough. For instance, Whisper utilized the largest publicly disclosed audio dataset, with 5 million hours (v3) of 'in the wild' data. However, even this dataset only approximates 33 billion text tokens, merely 0.2% of Llama 3's 15T token budget.
To overcome these challenges, we devoted significant effort to crawling speech data in the wild, preprocessing and cleaning the speech, and generating synthetic instruction pairs without TTS.
Data collection and processing
We sourced a diverse range of speech data (in descending order of size):
- Publicly available speech data from various online sources. We particularly emphasized high information density content and conversational audio. O(1M) hours.
- Academic ASR datasets (e.g., LibriSpeech, CommonVoice). O(100k) hours.
- High quality publicly available audio paired with human-written transcripts. O(10k) hours.
For the 'in the wild' datasets, we followed a multi-step cleaning procedure.
- Transcription and segmentation. We used WhisperX (Bain 2023) to create transcripts. The procedure uses voice activity detection (VAD) to remove segments without speech, eg silence or music. Then, we apply speaker segmentation.
- Text-based filtering and deduplication. Following other text pretraining work, we filter segments with high perplexity and duplicated segments. We use KenLM (Heafield 2010) to measure perplexity and MinHash-LSH (Broder 1997, Zhu 2024) to find duplicates.
- Force alignment for pauses (see following section).
Our deduplication efforts remove a large set of undesirable data. For example, Whisper often hallucinates "thanks for watching, don't forget to like and subscribe" from silence, a very common phrase in their training dataset. Oftentimes a audio segment contains an ad read, which is shared across segments from the same source. Our approach shows good precision and recall in removing these categories of segments; our results suggest around 20% of segments are generally removed this way.
To aid us in understanding the data and its quality, we also built a in-house annotation frontend. We built different views to annotate different aspects of the data, including speaker assignments and transcription edits. Here, we show the speaker assignment view, where an annotator would listen to the audio and swap speakers using keyboard shortcuts as the audio plays.
We placed an emphasis on obtaining high quality human transcripts. Human transcripts have better coverage of long-tail proper nouns and concepts but also often have idiosyncracies. For example, transcripts might contain speaker names or audio descriptions, which are not actually utterances.
To address these issues, we developed the following procedure:
- Transcription. We use WhisperX to create segmented transcripts with speaker identification and timestamps, similarly to the in the wild data.
- Mismatch filtering: we calculate the Levenshtein distance between the human and automatic transcript. If the distance is too large, we remove the segment.
- Alignment. Map filtered automatic transcripts to human transcripts with suffix arrays.
- Speaker assignment. We utilized speaker labels from the ground truth segments to map the corresponding filtered and aligned segments.
This process results in a high-quality, diverse dataset of speech and transcripts.
Instruction generation
We developed a variety of instruction tasks.
The easiest and largest source of instruction data is simple transcription. We randomly selected one of a variety of instruction formats for each instruction. Examples:
Repeat this back verbatim: {audio}{audio} \n\n Transcribe the previous segmentGiven this audio: \n\n{audio}\n\n What was said?
The bulk of our custom data was "document based questions" (DBQ). Document based questions are part of the AP US History curriculum, and involve a few pieces of historical context and questions that are meant to be answered from them, showcasing some level of additional memorized context and critical thinking. Similarly, we took audio segments from information-dense sources and generated training examples.
For a given audio segment, of 30-90 seconds, we prompted an LLM to first summarize the segment's transcript and to then generate a question and answer which could be answered using the segment as context. This process follows a Chain of Thought procedure to create a better question, but we reuse the model's intermediate summarization as a new instruction task for the SLM. Thus, we create two types of instructions:
-
Summary:
{audio} \n\n Summarize the key points of the above passage. -
DBQ:
Here is some context: {audio}. Given that context, answer this question: {question}
This is similar to the work in LibriSQA (Zhao 2023) and shares some philosophical similarities with 'backtranslation' (generating instruction from the result) and with retrieval-augmented instruction generation. The DBQ approach allows us to scale synthetic instruction pairs without needing to use synthetic audio, and maximizes the information gained from scarce audio.
Finally, we use a small amount of instruction data using synthetically generated audio. We find that perplexity filtering is a simple and effective way of filtering out low quality instructions, instructions which rely on code or math, or are in different languages. These synthesized instructions are then provided to the model directly, without any additional context.
Effect
These data processing techniques are highly scalable and efficiently utilize the limited available audio data. We believe that the techniques are highly sample efficient in training, especially with our high quality data collection. Because we did not have enough compute to train a competitive model on benchmarks, we focused on maximizing the quality of our data and processes, in the hopes of scaling the process up in the future.
Gondola
A downside of a cascaded system is that there are more components to manage state with. For instance, we need to continually stream audio from the user in and continually buffer the response from the assistant. Existing open-source implementations (eg Vocode) offered some inspiration, but were tricky to extend to business logic, eg saving utterances in a database or extending to RAG.
The orchestration system was mostly written in October and November 2024. We open-source a subset of our code under the AGPLv3 license. We additionally open-source our React library to interface with the backend under the MIT license.


We originally wrote Gondola to handle a traditional cascaded pipeline with ASR and process supervision (to guide the user through a structured conversation). In the traditional pipeline, ASR was a key part of the control flow, identifying when the user was done speaking and the bot should respond. Because Gazelle skips ASR, we needed to rewrite the library to move control flow elsewhere; we open-source this simplified version.
Gondola is written in Go. We found working with Go channels to be a more natural fit for message passing than Python async, which most other approaches used. Additionally, Golang interfaces meant that adding additional providers (eg a new TTS provider) took less than an hour of coding, significantly faster than an equivalent Python library.
Turn-taking prediction
Turn-taking in voice conversations remains a significant challenge for AI systems. Most existing solutions rely on simple voice activity detection (VAD), which struggles with long pauses and natural conversation flow. To address this limitation, we have developed a pause-aware Connectionist Temporal Classification (CTC) model that predicts whether a user has finished speaking or is merely pausing. Additionally, we propose a simple heuristic approach for generating backchannels, enhancing the naturalness of the conversation.
We employ word-level force alignment to determine precise timestamps
for each word and introduce special tokens to denote significant
pauses and turn endings. Specifically, we label pauses of one second
or longer where the same speaker retains the turn as
<pause>.
When a speaker's turn ends—defined as the next segment occurring
more than five seconds later or a different speaker beginning to talk,
we use the <endofturn> token. These special tokens
are incorporated into the CTC vocabulary, and the CTC objective
encourages the model to output these tokens as promptly as possible.
This mechanism enables the system to differentiate between a user who
is pausing and one who has completed their turn.
In our proposed implementation, the ASR model runs concurrently with
the main Speech-Language Model (SLM). We discard the intermediate
transcripts, as they are not necessary or particularly high quality
from greedy decoding, but we retain the special tokens. The system
then waits for either a predetermined delay or the
<endofturn> token before initiating a response.


In this example, I said "hey ... I have a question, uh, can you
tell me about the Roman Empire?". The model correctly inserts
<pause> after each pause. Think about this a bit
too: if somebody said that to you, how might you respond to the
pauses?
A key observation from labeling and reviewing the raw speech data was
that the pauses often corresponded with opportunities for
backchannels—short utterances like "yeah" or
"uh-huh" that listeners use to signal engagement. In the
previous example, the pauses fit Leveraging this insight, we can
prerecord a set of generic backchannels in the assistant's voice.
When the model produces a
<pause> token, we randomly issue a backchannel
utterance, subject to certain probabilities and minimum time intervals
between utterances.
We're releasing a
proof of concept model, finetuned from the wav2vec2 encoder. The labeling
approach is inspired by
Chang 2022, but we use
a simpler CTC objective when training our model. By reusing the same
frozen encoder as gazelle-v0.2, we can do one forward
pass through the encoder and pass the output directly to both the SLM
and CTC model. The model is quite undertrained (~100 hours of labeled
audio) - but shows that the technique is viable.
The importance of backchannels in voice AI systems cannot be overstated. Industry experiments with large-scale deployed voice AI systems have shown that user satisfaction and perceived quality significantly improve when the assistant employs backchannels. This feature was the first model we trained, bolstering our confidence in the overall system and serving as a key differentiator from most existing systems.
Prefill amortization
In AI voice chat, making the system feel real-time is paramount. The user's perceived latency is primarily determined by the time it takes for the system to reply and play the first audio segment. While some systems attempt to create an illusion of faster response times by inserting filler words like "uh-huh," we propose a more substantive solution to reduce actual response time.
The time to first audio token can be broken down into three main components: prefill time for audio units, decoding time for the first sentence, and text-to-speech (TTS) processing time. In our implementation, TTS is handled by third-party systems and cannot be modified, and decoding has already been heavily optimized. However, we identified significant potential for improvement in the prefill time, which typically consumed around 100-150ms in our initial tests.
We propose a simple technique to remove prefill latency when generating the speech-language model's response, without compromising output quality. Specifically, as user audio streams in, we propose incrementally prefilling the KV cache with the audio tokens. This method amortizes the total prefill cost over the duration of the user's speech, utilizing what would otherwise be idle processing time.
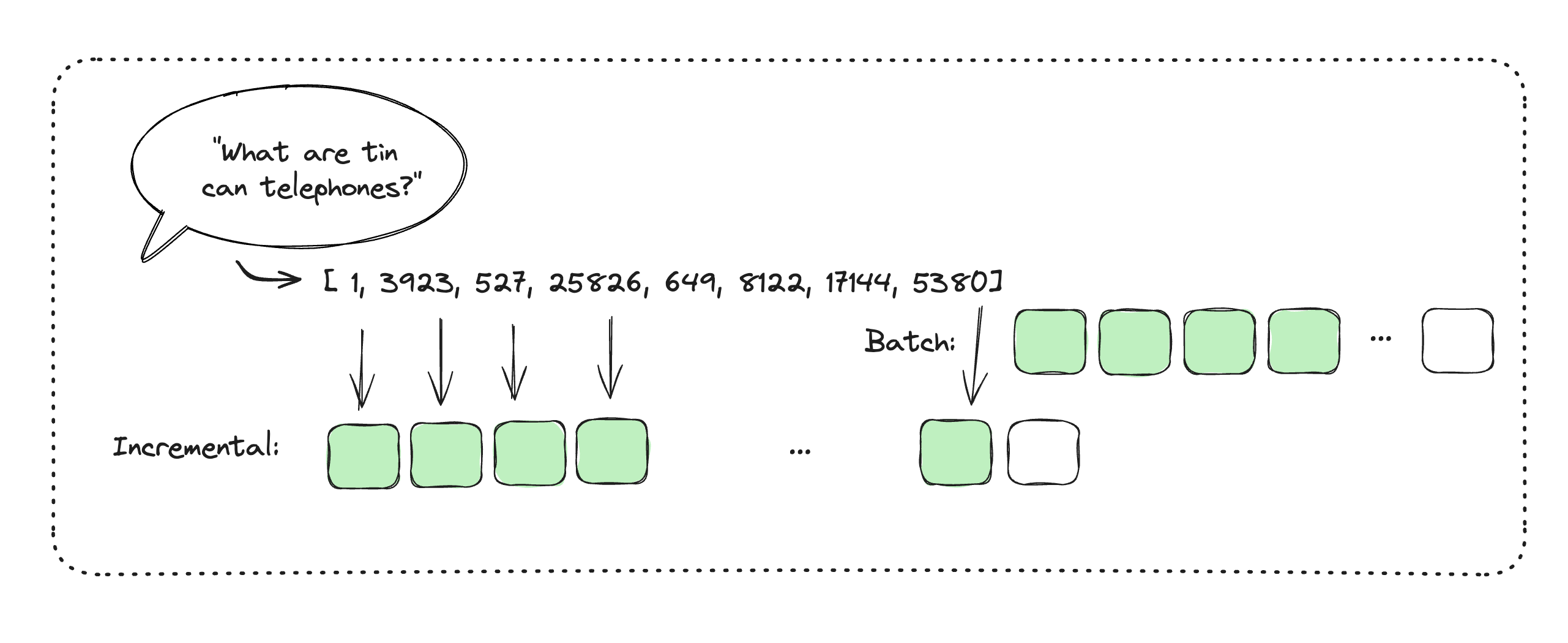
Traditional prefill methods involve a single forward pass in parallel over all input tokens to populate the KV cache. Our approach differs in that we don't have all input units available simultaneously, but we do know that the problem is monotonic. This allows us to run sequential forward passes for each input unit, or at some other predetermined cadence.
Our technique is similar to 'chunked prefill' (Agrawal 2023) but has quite different motivations. While chunked prefill typically aims to reduce memory costs for long sequences and sequence compute-bound prefill work with memory-bound decoding, we aim to reduce first token latency. Other applications tend to assume the entire input is passed at once, which is generally true in the text case. In the speech (and video) case, we can assume that we really are receiving the input continuously, and thus can perform this tradeoff to reduce first token latency.
The performance improvements will vary depending on hardware, sequence length, and model size, but the principle remains consistent across configurations. Note that the compute efficiency may decrease: computing over smaller batches reduces the arithmetic intensity, and we incur additional memory access costs in accessing the KV cache. We believe these drawbacks can be handled in a production system. In the batch size 1 case, the GPU is idle anyways; in the large batch size case, the prefill chunks can be batched with decoder tasks.
Our approach draws inspiration from Google Wave: Wave allowed users to see each other's typing in real-time, enabling dynamic editing and response formulation before the other party finished their message. This concept mirrors how humans listen and formulate responses during natural conversations, often beginning to think of replies before the speaker has finished.
We opensource a colab notebook demonstrating this technique and its speed up - on our example, it improves first token latency 2-3x.
Conclusion
We made a lot of progress towards a great AI voice chat, though there was still far to go. We certainly did not reach a global optimum but did prove that we could build something that worked and publicly derisked the research. From here, voice chat felt like a product and engineering problem, rather than a research question.
With everything put together, we would have had a state-of-the-art voice system responding in human imperceptible latency, capable of human-like backchannels and fluid turn-taking.